System architectures¶
The publication of OCDS data involves the creation of a conversion process. Like an ETL process, data has to be extracted from one or more sources, converted and either served or stored.
This process needs an adequate architecture to support it. Its design depends on several factors:
Whether existing systems can be updated, or new systems need to be created,
The number and nature of the data sources,
The technical resources available to the publisher, like storage and processing capabilities. This includes the availability of technical personnel to maintain new and updated systems.
Other considerations that affect the design are:
Individual OCDS documents for each process ought to be available at unique persistent URLs.
Bulk downloads in JSON, CSV (and, if appropriate, Excel) formats ought to be available. These files ought to be segmented according to one or more criteria, like time periods.
Users ought to be able to locate the collections of releases and records they want.
This guidance describes some design approaches with their advantages and disadvantages. This is not an exhaustive list, but it can be used to inform the design of the publication system.
On-demand transformation from data sources¶
In this scenario, data from each source is converted to OCDS format on-demand. OCDS data is not stored, but is created each time a user or third-party invokes the conversion process. This is the easiest path when a single source manages the data for all contracting processes. But it involves adding an OCDS conversion module.
An API performs data transformation on the fly each time it receives a request.
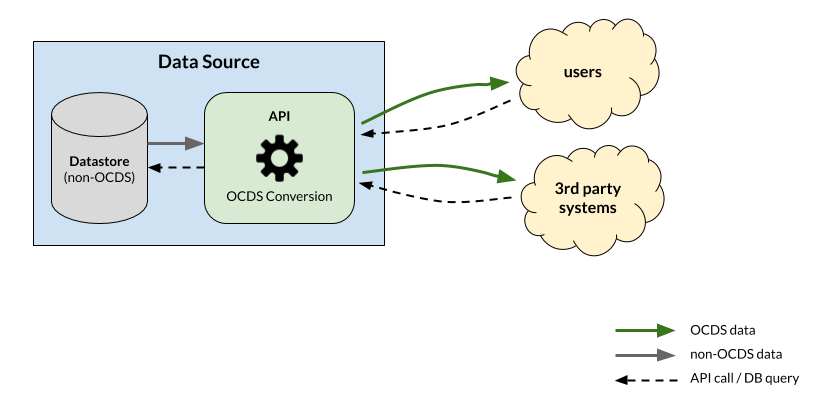
The conversion module produces OCDS releases and/or records wrapped in packages.
This approach does not need extra storage space. But it might not be possible to provide persistent URLs for releases, nor a change history for each process.
The easy releases guidance explains how to achieve a conformant OCDS implementation where it is not possible to provide a full change history.
Bulk downloads can be provided as part of the API. Live queries can stress the data sources if they need to scan large portions of data.
Separate OCDS datastore¶
In the scenarios that follow, a middleware component converts and stores the data in OCDS format. This has some advantages:
It is possible to merge and centralize data from more than one data source in a single datastore.
It can relieve data sources from expensive queries.
It can enable the generation of the change history for each contracting process.
On the other hand, there is a cost of maintaining a separate datastore. In these scenarios, we assume an API provides access to OCDS data.
Publishers need to consider how to store OCDS data. Releases are immutable so can be stored as they are, but records change over time. The process can build records on each API call, or store and update them each time a new release is created. The API needs to return OCDS data wrapped in a release or record package. Usually there is no need to store wrapped OCDS data, since package data can be generated in real time.
The releases and records guidance describes OCDS releases and records and their different components.
Pull and convert¶
In this scenario an automated process pulls data from the data sources to the middleware system. The middleware performs the conversion to OCDS and maintains a datastore in OCDS format.
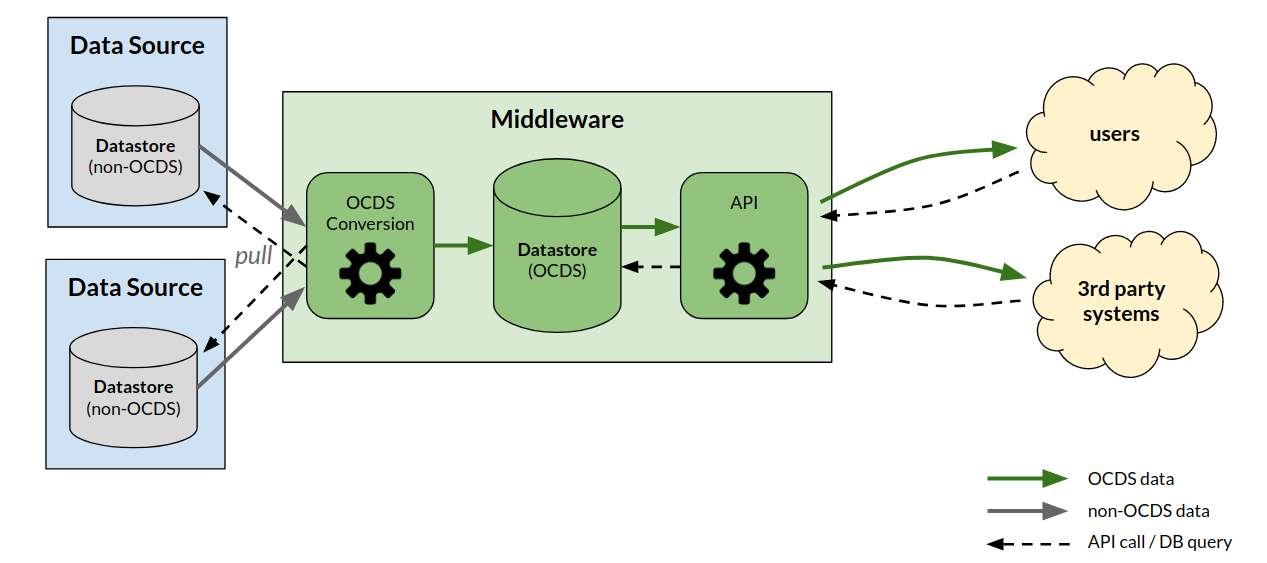
The key benefit of this approach is that the middleware system can store the change history. This is especially good when data sources do not maintain historic data.
This approach might involve some changes to data sources to allow the middleware to pull data. The middleware system merges and centralizes data in a single place.
To add more data sources, the OCDS conversion module needs to be updated to pull data from the new source(s).
An important decision in the implementation is the frequency to pull data. If the frequency is low, there is a risk of losing the detail of individual changes.
An alternative to the pull mechanism is to use a push mechanism in each data source. Specific events or changes to the data would trigger a data push to the middleware. This approach can mitigate the risk of losing individual changes. But this might involve bigger modifications to the data source(s).
European Dynamics developed an e-procurement system with a similar approach for OCDS output. The system was built for the Zambian Public Procurement Agency.
Convert and push¶
This scenario is a combination of the two previous scenarios. Data sources perform the conversion of data to OCDS format. They push converted data to a middleware, which maintains an OCDS format datastore. An API in the middleware system serves the OCDS data.
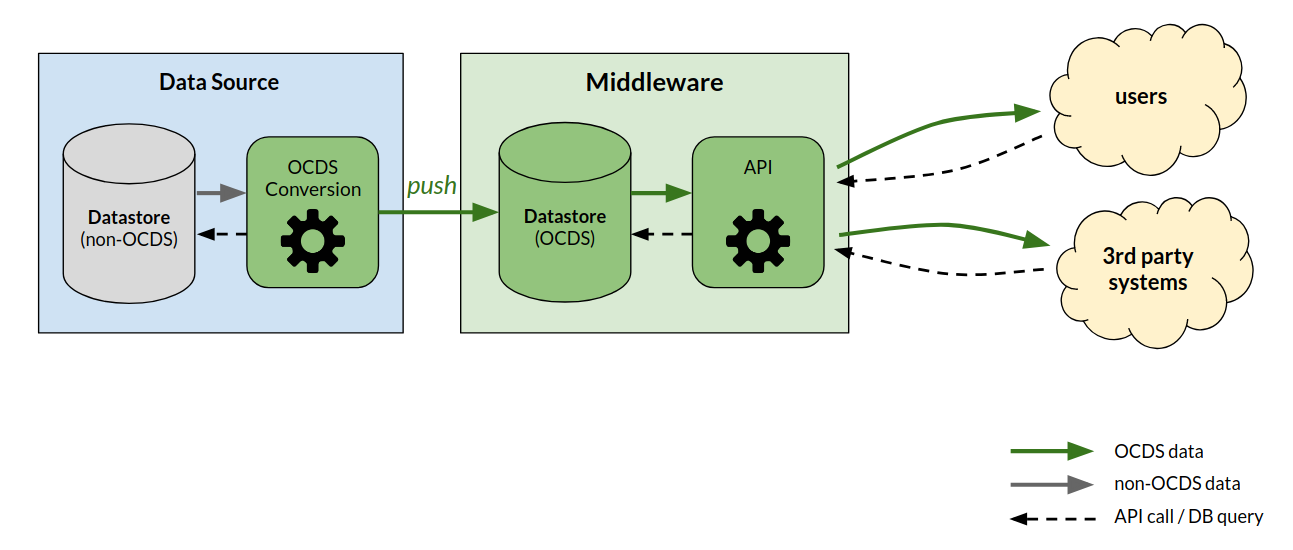
This approach puts the burden of data conversion on data sources. Yet it might be a solution for publishers with a single data source which does not store the change history.
This approach might also be suitable to combine data from many data sources. Each source becomes an OCDS publisher. The middleware becomes less complex since it only ingests data in a single format.
The OpenProcurement system adopted a similar approach. This system was developed in Ukraine and it's the base for the Prozorro platform. Prozorro uses OCDS building blocks as the foundation for data sources' data models.
A variant in this scenario is to store files in a web-accessible file system, as shown below. A periodical invocation of the conversion module updates the file system.
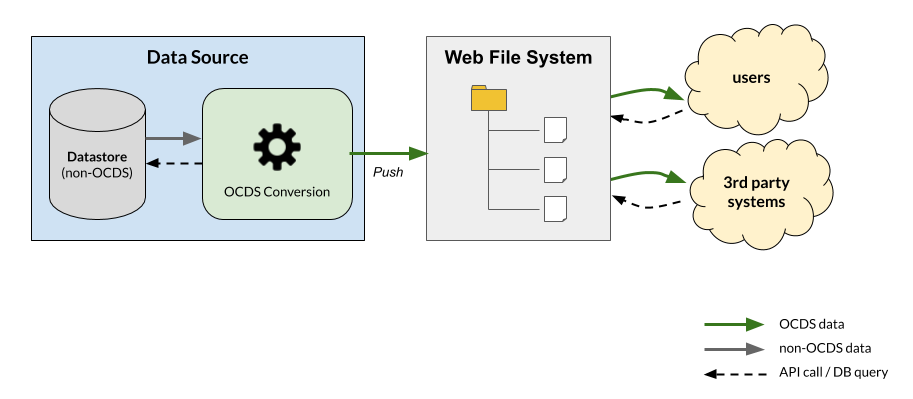
The file system ensures that each OCDS document has a persistent URL for access. But a downside is that the volume of data might grow fast, as plain files can take significant space. The file system can provide a change history as long as releases are never overwritten. Bulk downloads can be generated periodically and stored in the file system. Records might be impossible to produce if there is more than one system.
Manual import¶
In this scenario a middleware system sits between data sources and the API.
Data is manually exported from data sources into files. The files are uploaded to the middleware system, which converts the data to OCDS. The system stores the data in OCDS format.
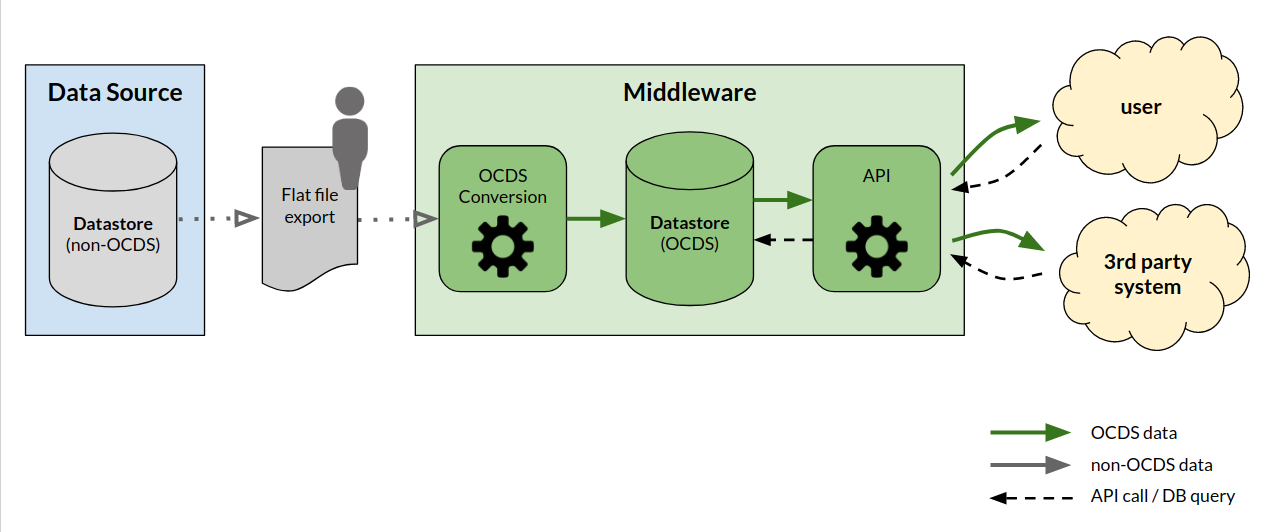
A disadvantage in this approach is the potential of failures. Input files might be corrupted or have unexpected formats due to changes or errors in the data sources.
There’s a documented example of this approach in the work Development Gateway did in Vietnam.
Additional considerations¶
When designing an architecture, publishers ought to consider the following:
Search endpoints. An API can provide more than individual releases and records. Endpoints help to filter data by different parameters like suppliers and product types. Another consideration is providing alternative formats, like CSV and Excel data. This is important for users who are more familiar with spreadsheets.
Documents. OCDS includes the disclosure of documents. Often, systems link out to documents on external platforms, where link-rot can set-in. The best systems will ensure that documents are archived but still available.